
JDK21版本
# JDK21版本
# 1、虚拟线程
虚拟线程在 JDK 19 版本中作为预览特性引入,旨在简化和改善 Java 的并发模型。
在JDK 21版本 虚拟线程已经被作为正式特性。
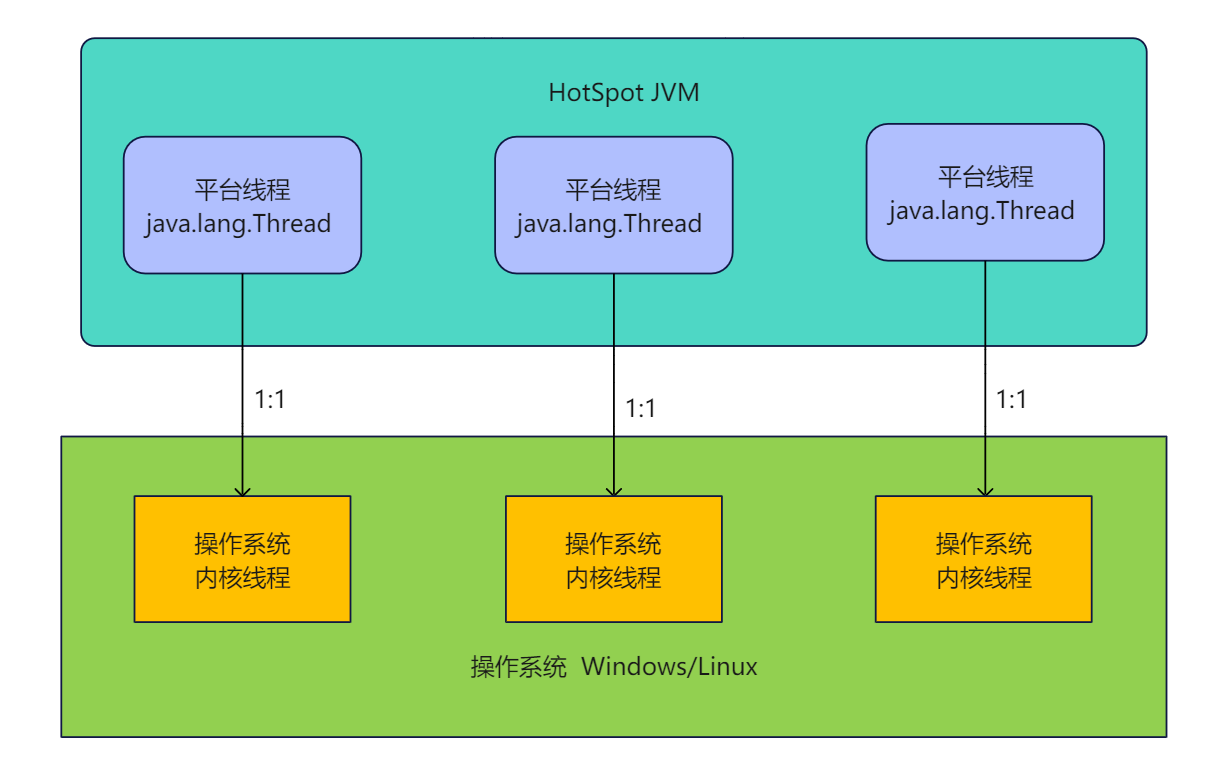
理解平台线程和系统内核线程的对应关系:
在JVM中 java.lang.Thread 就代表平台线程, HotSpot 虚拟机在Windows和Linux操作系统下,一个平台线程对应一个内核线程(在其他操作系统下 这个对应关系就不一定是1:1了)。
如下图所示:
平台线程的优劣势
优势:
| 优势 | 描述 | 举例 |
|---|---|---|
| 一对一映射 | 在JVM中,java.lang.Thread代表平台线程。HotSpot虚拟机在Windows和Linux操作系统下,一个平台线程对应一个内核线程。 | 每个Java平台线程对应一个由操作系统管理的内核线程。 |
| 多线程并发 | 平台线程允许Java程序进行并发操作,提高程序的并发能力和资源利用率。 | 可以在一个线程中进行网络请求,在另一个线程中进行文件读写。 |
| 硬件加速 | 平台线程可以利用操作系统的多核处理能力,实现真正的并行计算。 | 高性能计算应用程序可以通过多核处理实现并行计算。 |
劣势:
| 劣势 | 描述 | 举例 |
|---|---|---|
| 高开销 | 平台线程的创建和销毁成本较高,涉及操作系统级别的资源分配和管理。 | 服务器应用为每个请求创建一个新线程,消耗大量资源。 |
| 线程数量受限 | 操作系统能够支持的线程数量有限,在高并发场景下可能很快达到资源限制。 | 高并发Web服务器可能因线程资源耗尽而无法响应新请求。 |
| 阻塞问题 | 使用阻塞I/O操作时,平台线程会一直占用内核线程,导致资源浪费。 | 文件读写操作使用阻塞I/O时,线程在操作完成前一直阻塞。 |
| 上下文切换开销 | 平台线程的上下文切换开销较大,涉及寄存器、内存等资源的切换。 | 多线程应用频繁进行线程上下文切换,降低程序执行效率。 |
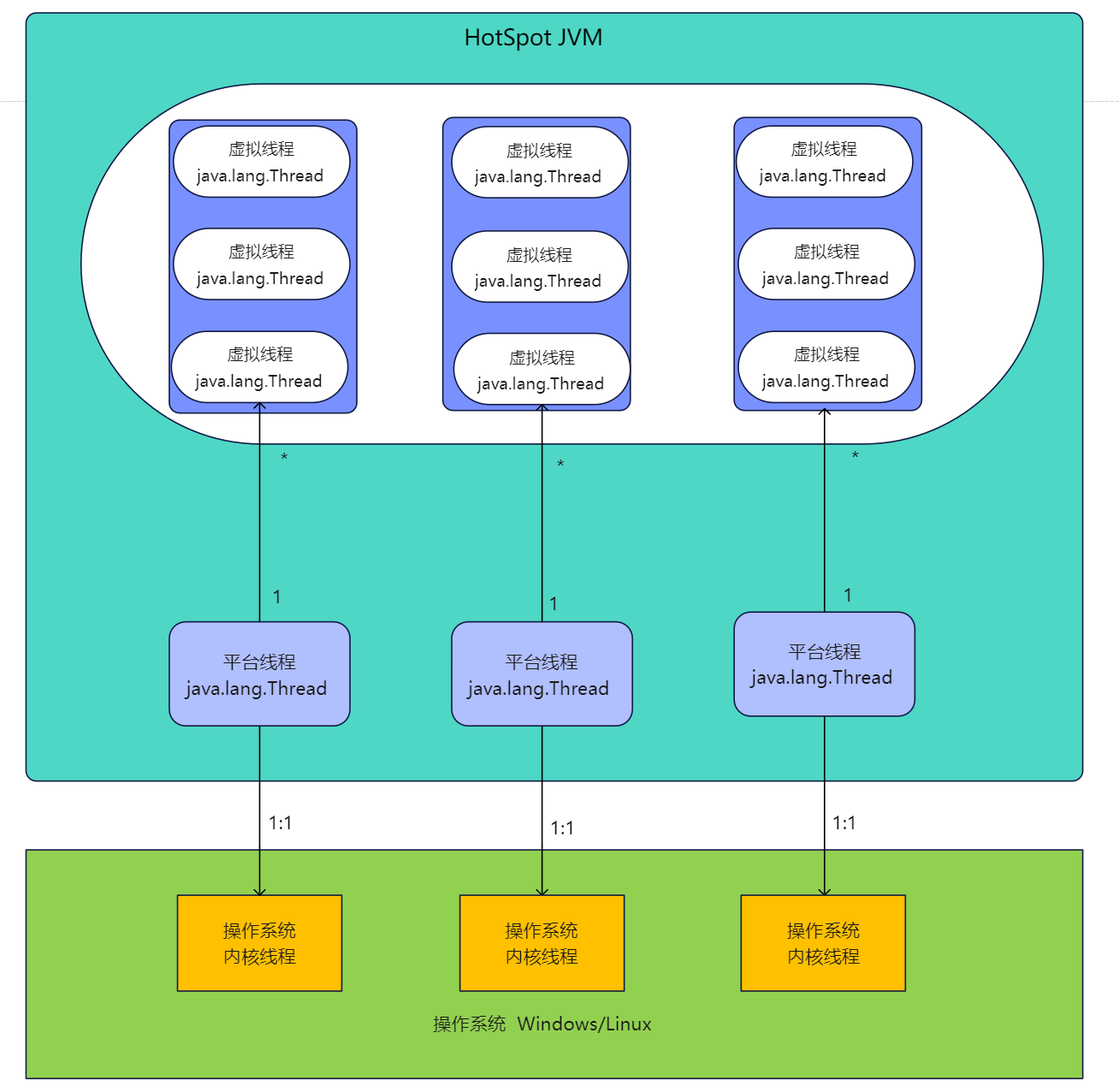
理解虚拟线程和平台线程的对应关系:
上面说了在JVM中 java.lang.Thread 就代表平台线程, 在JDK19开始引入虚拟线程后,为了使得虚拟线程的使用能够如同使用平台线程一样,所以 java.lang.Thread 也代表了虚拟线程,只是二者的创建方式和底层实现不同,对平台线程和虚拟线程的抽象都是用 java.lang.Thread 表示。
这么设计最直接的好处就是虚拟线程的API与平台线程相同,开发者无需学习新的并发模型或API,可以直接在现有代码中使用虚拟线程。这使得现有的多线程代码可以无缝地转换为使用虚拟线程。
如下图所示:
虚拟线程的优劣势
优势:
| 优势 | 描述 | 平台线程对比 |
|---|---|---|
| 轻量级 | 虚拟线程消耗的系统资源更少,可以在同一个JVM进程中创建和管理大量线程。(甚至可以创建上万数量级的虚拟线程) | 平台线程创建和销毁成本高,涉及操作系统级别的资源管理。 |
| 高并发 | 能够同时运行数万个虚拟线程,甚至更高,提高并发能力,特别适用于I/O密集型任务。 | 平台线程数量受限,高并发场景下可能达到系统资源限制。 但是平台线程更适合做密集计算和精细控制线程行为的场景 |
| 简单的同步编程 | 支持传统的同步阻塞编程模型,开发者无需学习新的并发模型,代码更易理解和维护。 | |
| 高效利用CPU | 虚拟线程在等待I/O操作时可以释放平台载体线程去执行其他任务,提高CPU利用率。 | 平台线程上下文切换开销较大,频繁切换会影响系统性能。 |
| 工具链兼容 | 调试器、分析工具和其他基于Thread API的工具无需修改即可支持虚拟线程。 | 平台线程已经广泛支持现有工具链,但管理和调试大量线程复杂且资源消耗大。 |
劣势:
| 劣势 | 描述 | 平台线程对比 |
|---|---|---|
| 性能不确定性 | 在某些极端情况下,虚拟线程的性能可能无法预期,需要实际测试和调整。 | 平台线程性能稳定,但由于高开销和数量限制,扩展性差。 |
总结下平台线程和虚拟线程的适用场景
平台线程的适用场景
| 场景 | 描述 | 示例 |
|---|---|---|
| 高性能计算 | 平台线程能够充分利用多核处理器的并行计算能力,适用于CPU密集型任务。 | 科学计算、图像处理、视频编码等需要大量计算资源的应用。 |
| 需要操作系统级特性的应用 | 平台线程可以直接利用操作系统提供的线程管理和调度功能,适用于需要与操作系统深度交互的任务。 | 低延迟、高可靠性的系统服务,如数据库管理系统、网络服务器等。 |
| 固定数量的并发任务 | 适用于并发任务数量相对固定且有限的场景,线程管理和资源开销可以接受。 | 传统的Web服务器、应用服务器等,处理相对少量并发请求。 |
| 阻塞I/O操作 | 虽然平台线程在阻塞I/O操作时会占用内核线程,但在某些情况下,平台线程的使用仍然合适。 | 需要处理少量阻塞I/O操作且对线程资源消耗不敏感的应用,如简单的文件读写操作。 |
虚拟线程的适用场景
| 场景 | 描述 | 示例 |
|---|---|---|
| 高并发、I/O密集型任务 | 虚拟线程可以轻松管理大量并发任务,特别适用于I/O密集型操作,如网络通信、文件读写等。 | 高并发的Web服务器、微服务架构中的各个服务节点。 |
| 轻量级并发任务 | 虚拟线程创建和销毁成本低,非常适合需要频繁创建和销毁线程的应用。 | 实时聊天应用、大规模的消息处理系统。 |
| 复杂的业务逻辑 | 虚拟线程支持简单的同步阻塞编程模型,使得编写和维护复杂的业务逻辑变得更加容易。 | 涉及复杂数据处理和业务流程的后台服务。 |
| 高扩展性要求 | 虚拟线程能够在不显著增加系统资源开销的情况下支持数万个并发任务,适用于需要高扩展性的应用。 | 物联网(IoT)平台、大规模在线游戏服务器。 |
| 资源受限环境 | 虚拟线程在资源受限的环境下表现出色,可以显著减少内存和CPU的使用。 | 嵌入式系统、边缘计算设备。 |
运行下面的代码 建议IDEA使用新点的版本,我使用的是IntelliJ IDEA 2023.3.6。
虚拟线程的创建代码示例:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
public class TestA {
public static void main(String[] args){
// 方式一、Thread.ofVirtual()
Thread thread = Thread.ofVirtual().name("虚拟线程").start(()->{
System.out.println("虚拟线程1执行任务");
});
// 方式二、Thread.startVirtualThread()
Thread.startVirtualThread(()-> System.out.println("虚拟线程执行任务"));
// 方式三、线程池
try (ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor();){
executorService.execute(()->{
System.out.println("虚拟线程执行任务");
});
} catch (Exception e) {
throw new RuntimeException(e);
}
//方式四、通过 ThreadFactory 创建
// 获取线程工厂类
ThreadFactory factory = Thread.ofVirtual().factory();
Thread newThread = factory.newThread(() -> {
System.out.println("虚拟线程执行任务");
});
newThread.start();
}
}
# 2、序列化集合
主要有以下三个接口:
SequencedCollection
SequencedSet
SequencedMap
目的是提供统一的方法来获取集合的第一个元素和最后一个元素。
下面用 ArrayList,LinkedHashSet,LinkedHashMap举例
import java.util.*;
public class TestA {
public static void main(String[] args) {
List<String> list = new ArrayList<>(Arrays.asList("1", "2", "3"));
System.out.println(list.getFirst()); // 1
System.out.println(list.getLast()); // 3
LinkedHashSet<String> hashSet = new LinkedHashSet<>();
hashSet.add("1");
hashSet.add("2");
hashSet.add("3");
System.out.println(hashSet.getFirst()); // 1
System.out.println(hashSet.getLast()); // 3
LinkedHashMap<String, String> map = new LinkedHashMap<>();
map.put("1","1");
map.put("2","2");
map.put("3","3");
System.out.println(map.firstEntry()); // 1=1
System.out.println(map.lastEntry()); // 3=3
}
}