
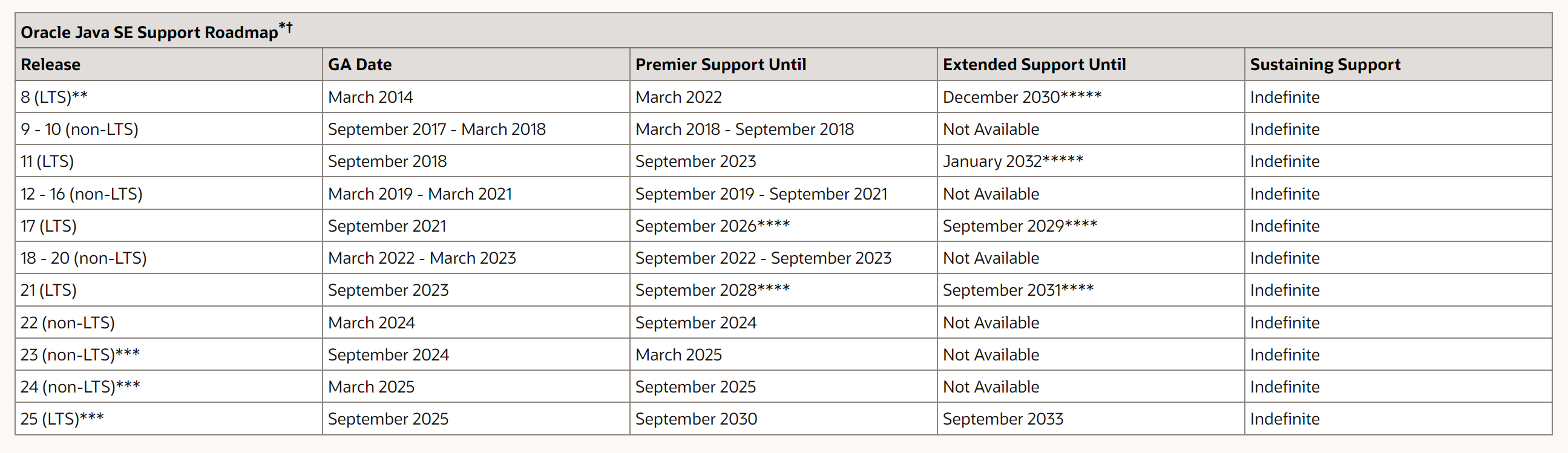
Oracle官网中JDK版本的说明,Java SE 8、11、17和21是LTS版本。也就是长期支持版本。
我们针对这几个版本了解学习下对应版本的新特性。
Oracle官网https://www.oracle.com/java/technologies/java-se-support-roadmap.html (opens new window)
# JDK8版本
正式发布于2014年。
比较重要的新增特性如下:
# 1、移除HotSpot虚拟机的永久代,使用元空间替代
永久代有固定的大小限制,在JDK8之前可通过JVM参数 -XX:MaxPermSize= xxx m 设置,当加载的类的大小超过这个限制时,就会抛出 OutOfMemoryError: PermGen space 错误。
这种设计限制了 Java 的灵活性和可伸缩性。
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。移除永久代主要是为了解决与类元数据存储相关的内存管理和性能问题。
元空间相比于永久代具有以下优势:
- 元空间基于本地内存不受 Java 堆内存大小的限制。
- 元空间的大小可以根据应用程序的需求动态调整,减少了内存溢出的风险,并允许应用更高效地管理内存。
# 2、Lambda 表达式
语法: Lambda 表达式基本语法如下:
(参数) -> 表达式 或者 (参数) -> { 代码块; }
作用: Lambda 表达式的主要作用是简化部分匿名内部类的写法。
特点:
- 参数无需声明类型: Lambda 表达式不需要声明参数类型,编译器可以自动推断参数类型。
- 参数括号可选: 当只有一个参数时,可以省略括号。当参数个数大于一个时,括号是必需的。空括号用于表示空参数集。
- 表达式的大括号可选: 当 Lambda 表达式的主体只包含一个表达式时,可以省略大括号。当表达式需要包含多个语句时,必需要使用大括号。
- return关键字可选: 当 Lambda 表达式主体只有一个表达式,且该表达式会自动返回结果时,可以省略 return 关键字。
Lambda 表达式用法的简单示例:
public static void main(String[] args) {
// ()表示空参数列表 且省略了 {}
Thread thread = new Thread(() -> System.out.println("Lambda表达式"));
Map<String, String> map = new HashMap<>();
map.put("123","123");
// (k,v) 表示参数列表 分别表示 Map的key的value
map.forEach((k,v)->{
System.out.println(k);
System.out.println(v);
});
// removeIf要求必需有返回值
List<String> list = new ArrayList<>();
list.removeIf((item)->{ return "1".equals(item);});
}
要理解Lambda 表达式的使用还需要了解一个知识点:函数式接口
# 3、函数式接口
函数式接口是**只包含一个抽象方法**的接口,它是在 Java 8 版本中引入的,其主要目的是支持函数式编程,有了函数式接口我们可以将函数作为参数传递、将函数作为返回值返回,同时也为使用 Lambda 表达式提供了支持。
标准的函数式接口使用@FunctionalInterface注解标注,例如:
@FunctionalInterface只是一个标记注解,可以让编译器检查接口是否符合函数式接口的定义。
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
对于无参数,无返回值的函数式接口的抽象方法, Lambda表达的用法如下:
public static void main(String[] args) {
// 之前我们对于内名内部类的用法
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("匿名内部类");
}
};
// Runnable中只有一个run方法 且无参,无返回值 使用Lambda表达式
Runnable runnable1 = ()->{
System.out.println("使用Lambda表达式");
};
}
从上面的代码可以看出 Lambda表达式本质上就是 函数式接口的实例。
可以把Lambda表达式理解为函数式接口实例化后的对象。
其他的函数式接口: 为了丰富Lambda表达式的应用场景,Java内置了许多函数式接口:
在JDK8之前,我们经常使用的函数式接口有:
java.lang.Runnable
java.util.concurrent.Callable
java.util.Comparator
java.lang.reflect.InvocationHandler
在 JDK8 中,新增的函数式接口在 java.util.function 包中:
下面举几个常见的例子:
java.util.function.Consumer:消费型接口
java.util.function.Function:函数型接口
java.util.function.Supplier:供给型接口
java.util.function.Predicate:断定型接口
这几个新增的函数式接口大大丰富了Lambda表达式的使用。
# Consumer 消费型接口
顾名思义,消费性接口肯定是拿到消息并消费,所以该接口中的方法,接收一个参数,但是没有返回值。
@FunctionalInterface
public interface Consumer<T> {
// 这个是抽象方法
void accept(T t);
// 这个是 default 修饰的实现方法 (这个也是JDK8的新特性 允许接口中有实现方法但是必需使用default 修饰)
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
Consumer 接口的用法:
Consumer 接口接收一个对象,可以在accept方法中对该对象进行操作,例如修改对象状态,打印该对象等。
该接口中的andThen方法接收一个Consumer对象,先执行调用者Consumer对象的accept方法,再执行传入的Consumer对象的accept方法。也就是一条消息可以被多个消费者依次消费处理。
public static void main(String[] args) {
Consumer consumer1 = (s) -> {
System.out.println(s);
};
consumer1.accept("消息1"); // 结果 消息1
Consumer c1 = (s) -> {
s = s + "c1";
System.out.println(s);
};
Consumer c2 = (s) -> {
s = s + "c2";
System.out.println(s);
};
c1.andThen(c2).accept("消息被处理");
// 结果 消息被处理c1
// 消息被处理c2
}
# Function函数型接口
Function 代表一个函数。
该接口包含一个抽象方法 R apply(T t),接受一个参数 t(类型为 T),并返回一个结果(类型为 R)
还包含3个实现方法
compose、andThen、identity
@FunctionalInterface
public interface Function<T, R> {
// 接收一个参数t ,返回一个参数R
R apply(T t);
// 接收一个Function类型的参数,调用接收参数的apply方法,返回Function
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
// 接收一个Function类型的参数,先调用自己的apply方法,再调用接收参数的apply方法
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
// 给啥返回啥
static <T> Function<T, T> identity() {
return t -> t;
}
}
Function接口的用法:
由于Function接口的apply方法接收的参数和返回的参数类型都是自定义的,所以可以用来做数据处理,参数的类型转换。
根据提供的compose方法和andThen方法 还可以做方法的链式调用。
至于给啥返回啥的identity方法,看似无用,实则还是有用的。
public static void main(String[] args) {
Function f1 = (t)->{
// ============== 类型转换
return Integer.parseInt((String) t);
};
Object apply = f1.apply("2024");
System.out.println(apply);
Function f2 = (t)->{
// ============== 数据处理
return (String)t + "数据处理";
};
String apply1 = (String) f2.apply("2024");
System.out.println(apply1);
// ============== 函数链式调用
Function chain1 = (t)->{
System.out.println("调用函数1");
return (String) t + 1;
};
Function chain2 = (t)->{
System.out.println("调用函数2");
return (String) t + 2;
};
Function chain3 = (t)->{
System.out.println("调用函数3");
return (String) t + 3;
};
// andThen 相当于从外到内顺序调用
String apply2 = (String) chain1.andThen(chain2).andThen(chain3).apply("0");
System.out.println(apply2);
// compose 相当于从内到外倒序调用
String apply3 = (String) chain1.compose(chain2).compose(chain3).apply("0");
System.out.println(apply3);
}
identity方法的妙用:
public static void main(String[] args) {
// ============ identity恒等函数的用法
ArrayList<Dog> dogs = new ArrayList<>();
dogs.add(new Dog("秀逗", "吃骨头"));
dogs.add(new Dog("四眼", "吃馒头"));
// 使用stream流 转map
// Dog::getName 方法引用 也是JDK8的新特性
// Function.identity() 我们想收集的map的value正好就是原对象
Map<String, Dog> dogMap = dogs.stream().
collect(Collectors.toMap(Dog::getName, Function.identity(), (k1, k2) -> k1));
System.out.println(dogMap);
}
class Dog {
private String name;
private String hobby;
public Dog(String name, String hobby) {
this.name = name;
this.hobby = hobby;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", hobby='" + hobby + '\'' +
'}';
}
}
# Supplier供给型接口
Supplier 有一个 get() 抽象方法,用于获取结果。不接收参数,返回一个结果。
@FunctionalInterface
public interface Supplier<T> {
T get();
}
Supplier 可以用于延迟加载。
代码示例:
public static void main(String[] args) {
Supplier supplier = () -> {
return "Result";
};
// 只有调用get方法时 才会真正的获取结果
System.out.println(supplier.get());
}
# Predicate断定型接口
Predicate接口中有个抽象方法test接收一个参数并返回一个布尔值。用于判断参数是否满足某种条件。
@FunctionalInterface
public interface Predicate<T> {
// 接收一个参数t 返回一个布尔值
boolean test(T t);
// 接收到一个 Predicate 类型的参数,先调用调用者自身的test方法再&&传入参数的test方法的结果并返回布尔值
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
// 调用test方法并取反
default Predicate<T> negate() {
return (t) -> !test(t);
}
// 接收一个 Predicate 类型的参数,先调用调用者自身的test方法再 || 传入参数的test方法的结果并返回布尔值
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
// 创建了一个 Predicate,它可以用来检查其他对象是否与给定的 targetRef 相等(如果 targetRef 非空)或是否都为 null(如果 targetRef 为空)。
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
Predicate接口的用法:
public static void main(String[] args) {
Predicate predicate = (s)->{
if("哈士奇".equals(s)){
return true;
}
return false;
};
Predicate predicat1 = (s)->{
String str = (String) s;
if(str.length()==3){
return true;
}
return false;
};
boolean test = predicate.test("哈士奇");
System.out.println(test); // true
boolean test1 = predicate.and(predicat1).test("哈士奇");
System.out.println(test1); // true
Predicate<Object> equal = Predicate.isEqual("哈士奇");
boolean test2 = equal.test("二哈");
System.out.println(test2); // false
}
# 其他的函数式接口
就不一一介绍了,了解了上面四个 自己再去看JDK源码就比较好了解其他函数式接口用途了。
# 4、方法引用
方法引用通过提供一种更加简洁、清晰的方式来引用方法,不仅提升了代码的可读性和可维护性,简化了代码的编写。
方法引用类型:
| 类型 | 格式 |
|---|---|
| 类的静态方法 | 类名::静态方法名 |
| 对象的实例方法 | 实例对象::方法名 |
| 类的实例方法 | 类名::实例方法名 |
| 类的构造器方法 | 类::new |
| 数组 | Type[]::new (Type表示数组的元素类型) |
如果使用IDEA编写程序,会有方法引用的提示。
代码示例:
public static void main(String[] args) {
// 类的静态方法引用
Runnable eat = Dog::eat;
eat.run();
// 对象的实例方法引用
Dog dog1 = new Dog();
Runnable drink1 = dog1::drink;
drink1.run();
// 类的实例方法引用
Consumer<Dog> drink = Dog::drink;
drink.accept(new Dog());
// 类的构造器方法引用
Supplier<Dog> dogSupplier = Dog::new;
Dog dog = dogSupplier.get();
// 数组引用
Function<Integer, int[]> function = int[]::new;
int[] arrays = function.apply(123);
}
class Dog {
private String name;
public static void eat() {
System.out.println("狗吃骨头!");
}
public void drink(){
System.out.println("狗喝水!");
}
}
# 5、Stream API
引入Stream API的目的是为了提高集合类型数据处理的效率和代码的简洁性。
Stream API的使用分为三步。
- ①、创建Stream流
- ②、对Stream进行中间操作
- ③、对Stream进行终端操作得到结果
# 创建Stream流
最常用的还是 通过集合的stream方法 创建Stream流
public static void main(String[] args) {
List<String> list = new ArrayList<>(Arrays.asList("1", "2", "3"));
// 通过集合的stream方法 创建Stream流
Stream<String> stream = list.stream();
// 通过 Arrays.stream方法 获取数组的 stream流
IntStream stream1 = Arrays.stream(new int[]{1, 2, 3});
// 使用 Stream.of方法
Stream<String> stream2 = Stream.of("1", "2", "3");
// 使用 Stream.builder方法
Stream.Builder<Object> builder = Stream.builder();
builder.accept("1");
builder.accept("2");
builder.accept("3");
Stream<Object> stream3 = builder.build();
}
# 中间操作
常用的中间操作:
| 方法名 | 描述 |
|---|---|
| map(Function<T, R> mapper) | 将元素通过给定的函数映射为另一个类型的元素 |
| filter(Predicate | 根据给定的条件过滤元素 |
| distinct() | 去除流中的重复元素 |
| sorted() | 对元素进行排序,默认按自然顺序排序 |
| sorted(Comparator | 使用自定义比较器对元素进行排序 |
| limit(long maxSize) | 截取流中的前 maxSize 个元素 |
| skip(long n) | 跳过流中的前N个元素 |
| flatMap(Function<T, Stream | 将每个元素映射为一个流,然后将这些流合并为一个流 |
中间操作代码示例:
public static void main(String[] args) {
List<Dog> list = new ArrayList<>();
Dog dog1 = new Dog("秀逗", 8);
Dog dog2 = new Dog("四眼", 4);
Dog dog3 = new Dog("四眼狗", 4);
Dog dog4 = new Dog("哈士奇", 4);
list.add(dog1);
list.add(dog2);
list.add(dog3);
list.add(dog4);
// ======================= 中间操作 =============================
// map中间操作 将Dog元素 映射成 Dog中的name元素
list.stream().map(Dog::getName);
// filter中间操作 根据给定的条件过滤元素
list.stream().filter((item) -> {
return item.getAge() > 4;
});
// distinct() 去重 去重的标准是基于对象的equals()和hashCode()方法
list.stream().distinct();
// sorted() 对元素进行排序,默认按自然顺序排序
list.stream().sorted();
// sorted(Comparator comparator) 使用自定义比较器对元素进行排序
// 先按照年龄倒序,再按照姓名正序
list.stream().sorted(Comparator.comparing(Dog::getAge).reversed()
.thenComparing(Dog::getName));
// 自定义 Comparator
Stream<Dog> sorted = list.stream().sorted((o1, o2) -> {
// 先比较年龄 按照年龄从小到大排序
int compareAge = Integer.compare(o1.getAge(), o2.getAge());
if (compareAge != 0) {
return compareAge;
}
// 再比较名字长度
int nameLength = Integer.compare(o1.getName().length(), o2.getName().length());
if (nameLength != 0) {
// 长度长的在前面
return -nameLength;
}
// 再自定义一个 如果名字里包含 哈士奇就排在前面
boolean b1 = o1.getName().contains("哈士奇");
boolean b2 = o2.getName().contains("哈士奇");
// b1包含哈士奇 b1排在前面
// 返回负数(如-1),表示第一个参数(在本例中是o1)应该排在第二个参数(o2)之前。
//返回正数(如1),表示第一个参数应该排在第二个参数之后。
//返回0,表示两者相等,对于排序而言,它们的相对位置不变
if (b1 && !b2) {
return -1;
}
// b2包含哈士奇 b2排在前面
if (!b1 && b2) {
return 1;
}
return 0;
});
// limit(n) 截取前n个元素
list.stream().limit(2);
// skip(long n) 跳过前n个元素
list.stream().skip(2);
// flatMap(Function<T, Stream> mapper) 将每个元素映射为一个流,然后将这些流合并为一个流
// 相当于把有层级的 对象 都扁平化 消除层级
List<List<Dog>> arrayLists = new ArrayList<>();
arrayLists.add(new ArrayList<>(Arrays.asList(dog1,dog2,dog3)));
arrayLists.add(new ArrayList<>(Arrays.asList(dog4)));
arrayLists.stream().flatMap(List::stream);
}
# 终端操作
| 方法名 | 描述 |
|---|---|
| collect() | 将流中的元素收集到集合或映射中,可以指定收集器来定制收集行为 |
| forEach() | 对流中的每个元素执行指定的操作 |
| forEachOrdered() | 与forEach类似,当使用parallelStream(并行流时)遍历时保留了元素的顺序 |
| toArray() | 将流中的元素收集到数组中 |
| reduce(accumulator) | 通过累积操作将流中的元素归约为单个结果 |
| reduce(identity, accumulator) | 使用初始值和累积操作将流中的元素归约为单个结果 |
| reduce(identity, accumulator, combiner) | 使用初始值、累积操作和组合操作将流中的元素归约为单个结果 |
| min(comparator) | 使用指定的比较器找到流中的最小元素 |
| max(comparator) | 使用指定的比较器找到流中的最大元素 |
| count() | 计算流中元素的数量 |
| anyMatch() | 检查流中是否有任何元素匹配指定的条件 |
| allMatch() | 检查流中的所有元素是否都匹配指定的条件 |
| noneMatch() | 检查流中是否没有元素匹配指定的条件 |
| findFirst() | 返回流中的第一个元素(如果存在),通常与filter操作一起使用 |
| findAny() | 返回流中的全部符合条件的元素(如果存在),通常与filter操作一起使用 |
终端操作代码示例:
public static void main(String[] args) {
Dog dog1 = new Dog("秀逗", 8);
Dog dog2 = new Dog("四眼", 4);
ArrayList<Dog> dogs = new ArrayList<>();
dogs.add(dog1);
dogs.add(dog2);
// =============== 终端操作 ===================
// ============= collect() 将流中的元素收集到集合或映射中,可以指定收集器来定制收集行为
// 收集Set
Set<String> dogSet = dogs.stream().map(Dog::getName).collect(Collectors.toSet());
// 收集List
List<String> dogList = dogs.stream().map(Dog::getName).collect(Collectors.toList());
// 收集Map
Map<String, Dog> dogMap = dogs.stream().collect(Collectors.toMap(Dog::getName, Function.identity(), (k1, k2) -> k1));
// 收集分组
Map<String, List<Dog>> dogGroup = dogs.stream().collect(Collectors.groupingBy(Dog::getName));
// ========== forEach 对流中的每个元素执行指定的操作
dogs.forEach(System.out::println);
// ========== forEachOrdered 与forEach类似,当使用parallelStream(并行流时)遍历时保留了元素的顺序
dogs.parallelStream().forEachOrdered(System.out::println);
// ========== toArray 将流中的元素收集到数组中
dogs.toArray();
// ========== reduce(accumulator) 通过累积操作将流中的元素归约为单个结果
List<String> list = Arrays.asList("1", "2", "3");
list.stream().reduce((a,b)-> a+b);
// ========== reduce(identity, accumulator) 使用初始值和累积操作将流中的元素归约为单个结果
dogs.stream().mapToInt(Dog::getAge).reduce(0, Integer::sum);
// ========== reduce(identity, accumulator, combiner) 使用初始值、累积操作和组合操作将流中的元素归约为单个结果
dogs.parallelStream()
.map(Dog::getAge) // 将Dog流转换为年龄的IntStream
.reduce(0, // 初始值 identity
Integer::sum, // 累积器 accumulator,直接使用Integer的sum方法进行累加
Integer::sum // 组合器 combiner,也是sum方法,用于并行处理时合并子结果
);
// ========== min(comparator) 使用指定的比较器找到流中的最小元素
dogs.stream().min(Comparator.comparing(Dog::getAge));
// ========== max(comparator) 使用指定的比较器找到流中的最大元素
dogs.stream().max(Comparator.comparing(Dog::getAge));
// ========== count() 计算流中元素的数量
dogs.stream().count();
// ========== anyMatch() 检查流中是否有任何元素匹配指定的条件|
dogs.stream().anyMatch((item)->{return item.getName().contains("哈士奇");});
// ========== allMatch() 检查流中的所有元素是否都匹配指定的条件
dogs.stream().allMatch((item)->{return item.getName().contains("哈士奇");});
// ========== noneMatch() 检查流中是否没有元素匹配指定的条件
dogs.stream().noneMatch((item)->{return item.getName().contains("哈士奇");});
// ============ findFirst 返回流中的第一个元素(如果存在),通常与filter操作一起使用
dogs.stream().filter((item)->{return item.getName().contains("哈士奇");}).findFirst();
// ============ findAny 返回流中的全部符合条件的元素(如果存在),通常与filter操作一起使用
dogs.stream().filter((item)->{return item.getName().contains("哈士奇");}).findAny();
}
# 6、Optional 类
Optional 类本质上是一个容器类,用来更优雅的处理可能出现的空指针问题。
# Optional 使用建议:
避免将Optional用作方法的参数或返回类型: Optional应该用于表示可能为null的值,而不是作为方法的参数或返回类型。
在方法签名中使用Optional可能会使代码变得复杂,并且不符合Optional的设计初衷。使用isPresent()和ifPresent()进行判断: 在使用Optional时,最好使用isPresent()方法来检查Optional是否包含值,然后使用ifPresent()方法来执行相应的操作。
这样可以避免使用get()方法,从而避免潜在的空指针异常。避免滥用Optional: Optional并不是解决所有空指针问题的银弹。在某些情况下,使用传统的null检查可能更加简单和清晰。
Optional应该用于表示可能为null的值,并且仅在需要对null进行特殊处理时使用。使用orElse()和orElseGet()提供默认值: 在使用Optional时,可以使用orElse()方法或orElseGet()方法来提供一个默认值,以防Optional为空。
orElse()方法在Optional为空时会返回默认值,而orElseGet()方法在Optional为空时会执行一个Supplier函数来生成默认值。
代码示例:
public static void main(String[] args) {
Dog dog = new Dog("Buddy", 3);
// 创建一个Optional实例
Optional<Dog> optionalDog = Optional.ofNullable(dog); // 确定有值时使用of,否则使用empty或ofNullable
// 1. isPresent() 和 get()
if (optionalDog.isPresent()) {
System.out.println("Dog's name: " + optionalDog.get().getName());
}
// 2. ifPresent(Consumer)
optionalDog.ifPresent(d -> System.out.println("Dog's age: " + d.getAge()));
// 3. map(Function)
Optional<String> dogNameOpt = optionalDog.map(Dog::getName);
dogNameOpt.ifPresent(System.out::println); // 输出狗的名字
// 4. flatMap(Function)
// 假设有个方法返回Optional<Integer>
Optional<String> mappedAgeOpt = optionalDog.flatMap(Dog::getOptionalName);
mappedAgeOpt.ifPresent(name -> System.out.println("Mapped name: " + name));
// 5. orElse(T)
String dogNameOrDefault = optionalDog.map(Dog::getName).orElse("Unknown");
System.out.println("Dog name or default: " + dogNameOrDefault);
// 6. orElseGet(Supplier)
String dogNameOrDefaultGet = optionalDog.map(Dog::getName).orElseGet(() -> "Fallback");
System.out.println("Dog name or default via Supplier: " + dogNameOrDefaultGet);
// 7. orElseThrow(Supplier)
try {
Dog dog1 = (Dog)Optional.empty().orElseThrow(() -> new IllegalArgumentException("Dog is missing"));
} catch (IllegalArgumentException e) {
System.out.println(e.getMessage());
}
}
}
@Data
class Dog {
private String name;
private Integer age;
public Dog(String name, Integer age) {
this.name = name;
this.age = age;
}
public Optional<String> getOptionalName() {
return Optional.ofNullable(name);
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
# 7、LocalDate、LocalDateTime和DateTimeFormatter
在JDK8之前 处理日期、时间和格式化日期时间,使用 java.util.Date 、java.util.Calendar、java.text.SimpleDateFormat 这三个类。
为什么JDK8要引入 LocalDateTime 和 DateTimeFormatter呢?
有以下几个原因:
①、线程不安全: java.util.Date 和 java.util.Calendar 线程不安全,这就导致我们在多线程环境使用需要额外注意。
且java.util.Date类是可变的,我们可以随时修改它,如果不小心就会导致数据不一致问题。
java.text.SimpleDateFormat 也是线程不安全的,这可能导致日期格式化错误。而且它的模式字符串容易出错,不够直观。②、时区处理问题: Java 8 版本以前的日期 API 在时区处理上存在问题,例如时区转换和夏令时处理不够灵活和准确。
而且时区信息在 Date 对象中存储不明确,这使得正确处理时区变得复杂。
# LocalDate、LocalDateTime和DateTimeFormatter的使用示例:
public static void main(String[] args) {
// 获取当前时间
LocalDateTime now = LocalDateTime.now();
// 自定义格式化器
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
String format = formatter.format(now);
System.out.println(format);
// 通过格式化器 解析字符串 日期时间
LocalDateTime parse1 = LocalDateTime.parse("2024-05-20 12:00:00", formatter);
System.out.println(parse1);
LocalDate date = LocalDate.now();
// 自定义格式化器
DateTimeFormatter formatterDate = DateTimeFormatter.ofPattern("yyyy-MM-dd");
String formatDateStr = formatterDate.format(date);
System.out.println(formatDateStr);
// 通过格式化器 解析字符串 日期时间
LocalDate date1 = LocalDate.parse("2024-05-20", formatterDate);
System.out.println(date1);
}
# 使用DateTimeFormatterBuilder构造特殊的解析器
构建一个能够解析两种格式的日期解析器 yyyy-MM-dd 和 yyyy/MM/dd
public static void main(String[] args) {
// 构建一个能够解析两种格式的日期解析器
// DateTimeFormatterBuilder 使用了方括号 [ ] 来定义备选的格式模式。
// 这样构建的解析器会尝试按照提供的顺序匹配每一种模式,直到成功解析为止
DateTimeFormatter formatter = new DateTimeFormatterBuilder()
.appendPattern("[yyyy-MM-dd]")
.appendPattern("[yyyy/MM/dd]")
.toFormatter();
String dateStr1 = "2024-05-27";
String dateStr2 = "2024/05/27";
try {
LocalDate date1 = LocalDate.parse(dateStr1, formatter);
System.out.println("Parsed date 1: " + date1); // Parsed date 1: 2024-05-27
LocalDate date2 = LocalDate.parse(dateStr2, formatter);
System.out.println("Parsed date 2: " + date2); // Parsed date 1: 2024-05-27
} catch (DateTimeParseException e) {
System.err.println("Error parsing date: " + e.getMessage());
}
}